如何优化神经网络?(加快训练速度,提高准确度)
如何优化神经网络?(加快训练速度,提高准确度)
有钱:
Auto ML自动调参(20美元/小时,听说这个调参似乎挺耗时的…)
人工调参:
1)数据输入:
最优加速性能不仅依赖于高速的计算硬件,也要求有一个高效的数据输入管道。要解决I/O传输问题,有几个方面:SSD、缓冲池、数据读入及处理和模型计算并行起来
2)大batch size:
为了充分利用大规模集群算力以达到提升训练速度的目的,人们不断的提升batch size大小,这是因为更大的batch size允许我们在扩展GPU数量的同时不降低每个GPU的计算负载。然而,过度增大batch size会带来明显的精度损失!这是因为在大batch size(相对于训练样本数)情况下,样本随机性降低,梯度下降方向趋于稳定,训练就由SGD向GD趋近,这导致模型更容易收敛于初始点附近的某个局部最优解,从而抵消了计算力增加带来的好处。
解决方向:Learning Rate自适应
3)防止模型过拟合:
a. 添加Batch normalization层:用以规范特征的分布,使输出的特征图分布更加均匀。这个效果一般不错。
b. 对参数做正则化:其他防止模型过拟合的策略比如对参数做正则化,包括weight, bias, BN beta和gamma,这些参数占模型所有参数的比例可能很小,比如在AlexNet模型,它们仅占总参数量的0.02%,对这些参数进行正则化会增加计算量,还会让模型损失一些灵活性。
c. dropout:dropout可阻碍网络学习仅存在于训练集中局部的“额外规律”,这个效果比较强,但如果加的dropout层过多,比如每层后面都加一个dropout,阻碍网络学习规律的强度也会增加。
4)Inception 结构
Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益。参考ResNet变形,GoogLeNet,SENet等。
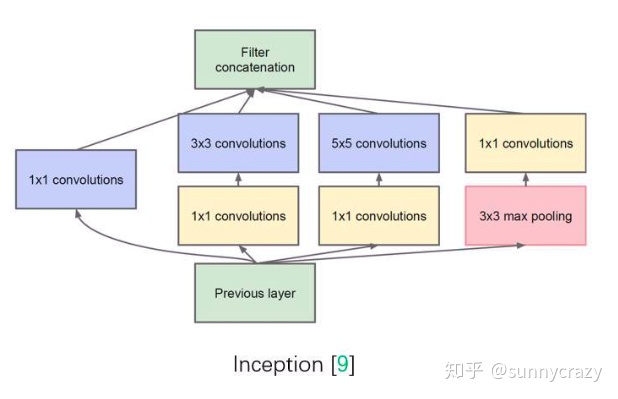
Inception结构
5)权重初始化
权重初始化决定了网络从什么位置开始训练,良好的起始位置不仅可以减少训练耗时,也可以使模型的训练更加稳定,并且可以避开很多训练上的问题。比如“dying ReLU”问题,Relu可能会使节点无法被激活,那么就需要对w权重进行合理的初始化;还可以使用leaky relu函数解决。
6)超参调优
- 参数步长由粗到细:调优参数值先以较大步长进行划分,可以减少参数组合数量,当确定大的最优范围之后再逐渐细化调整,例如在调整学习速率时,采取较大步长测试发现:学习率lr较大时,收敛速度前期快、后期平缓,lr较小时,前期平缓、后期较快,根据这个规律继续做细微调整,最终得到多个不同区间的最佳学习速率;
- 低精度调参:在低精度训练过程中,遇到的最大的一个问题就是精度丢失的问题,通过分析相关数据,放大低精度表示边缘数值,保证参数的有效性是回归高精度计算的重要方法;
- 初始化数据的调参:随着网络层数的增多,由于激活函数的非线性,初始化参数使得模型变得不容易收敛,可以像VGGNet那样通过首先训练一个浅层的网络,再通过浅层网络的参数递进初始化深层网络参数,也可以根据输入输出通道数的范围来初始化初始值,一般以输入通道数较为常见;对于全连接网络层则采用高斯分布即可;对于shortcut的batch norm,参数gamma初始化为零。
还有其他细节,比如每一个epoch就shuffle训练数据等,想要优化神经网络,加快训练速度,提高准确度,更重要的是创造更好的网络结构,更有优的公式。
参考资料:
【1】机器之心:https://zhuanlan.zhihu.com/p/40993775
【2】YJango的前馈神经网络:https://zhuanlan.zhihu.com/p/27854076
【3】CS231n Convolutional Neural Networks for Visual Recognition:http://cs231n.github.io/convolutional-networks/